I travel quite a lot, and I’ve developed the habit of always texting myself my hotel room number so I don’t forget it (unfortunately, I really do stay in that many hotels).
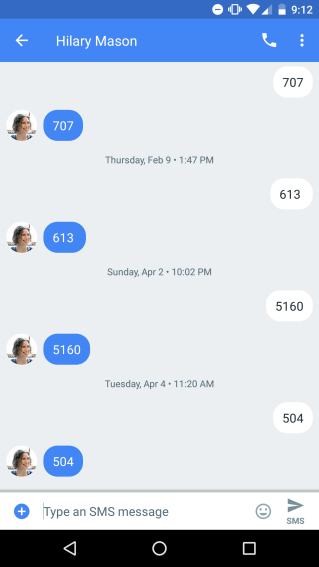
I recently looked at my texts to myself and realized it seems like a reasonable set of random numbers. Hello, hotel-based entropy*!
What can you do with a very very very slow random number generator? You could spend a lifetime generating enough random digits to encrypt a document (you can seed a pseudorandom number generator, of course, but what’s the fun in that?).
* Okay, this is a really bad idea. For one thing, I only have seven numbers right now, and that’s not even enough to run against any of the dieharder tests. For another, they aren’t at all random, as there’s a bias in the number of floors and number of rooms in various hotels. Also, 5160 was in Vegas, and so even though I was told to go to the “51st floor” when I got off the elevator and looked out the window I was on the third floor. Vegas is weird. If you do actually want some real random numbers, check out the NIST Randomness Beacon. Not my hotel rooms.
** Okay, here are the actual numbers:
11085
12321
707
613
5160
504
pack glasses
1534

